Pick the right Azure GPT model
in minutes, not weeks.
Stop guessing your monthly bill. YSelector gives you the exact performance-to-price ratio for every GPT model on Azure, so you can choose the most efficient stack for your budget.
Architecture Simulation
Full RAG Pipeline
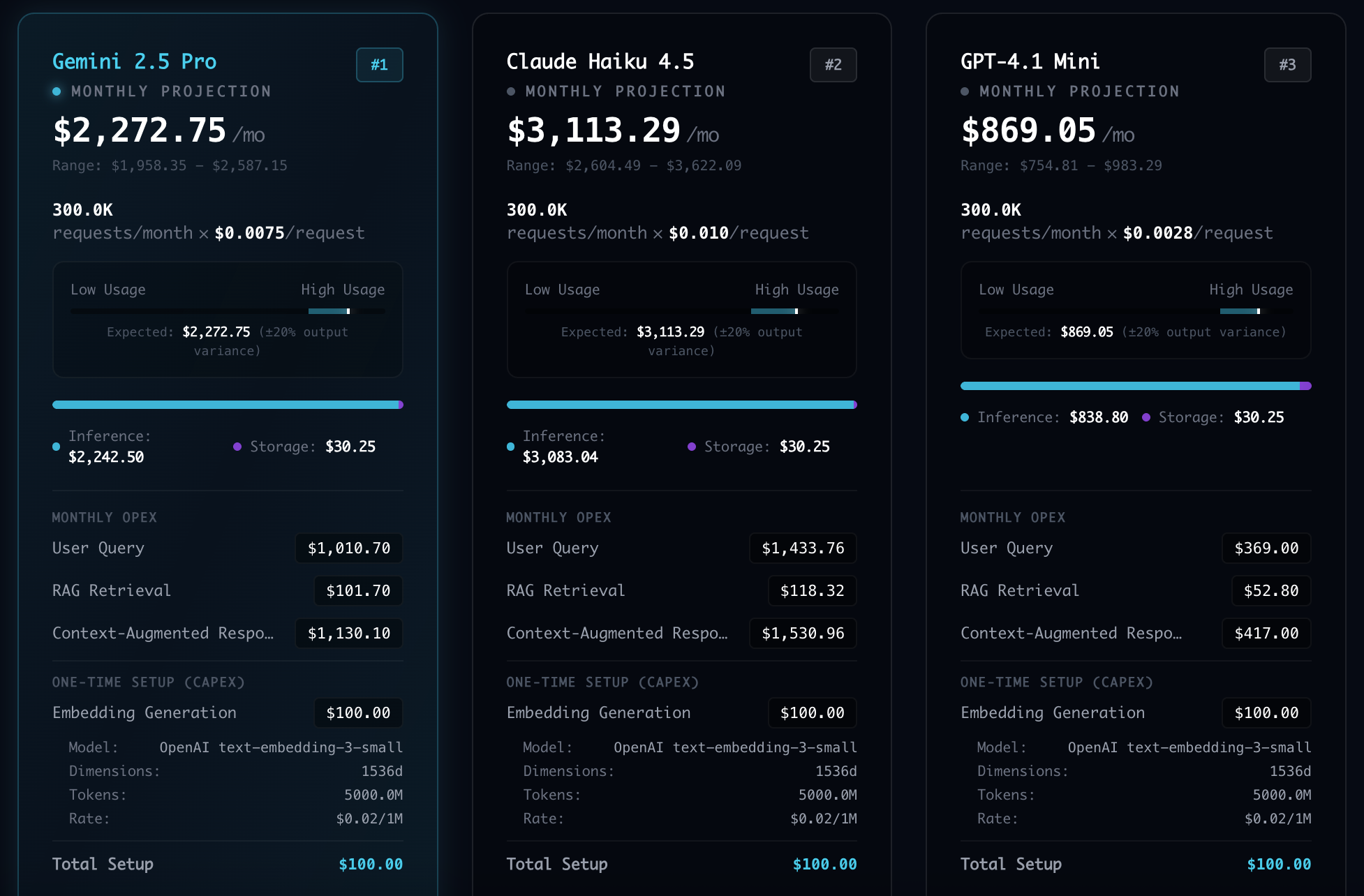
Cost Modeling.
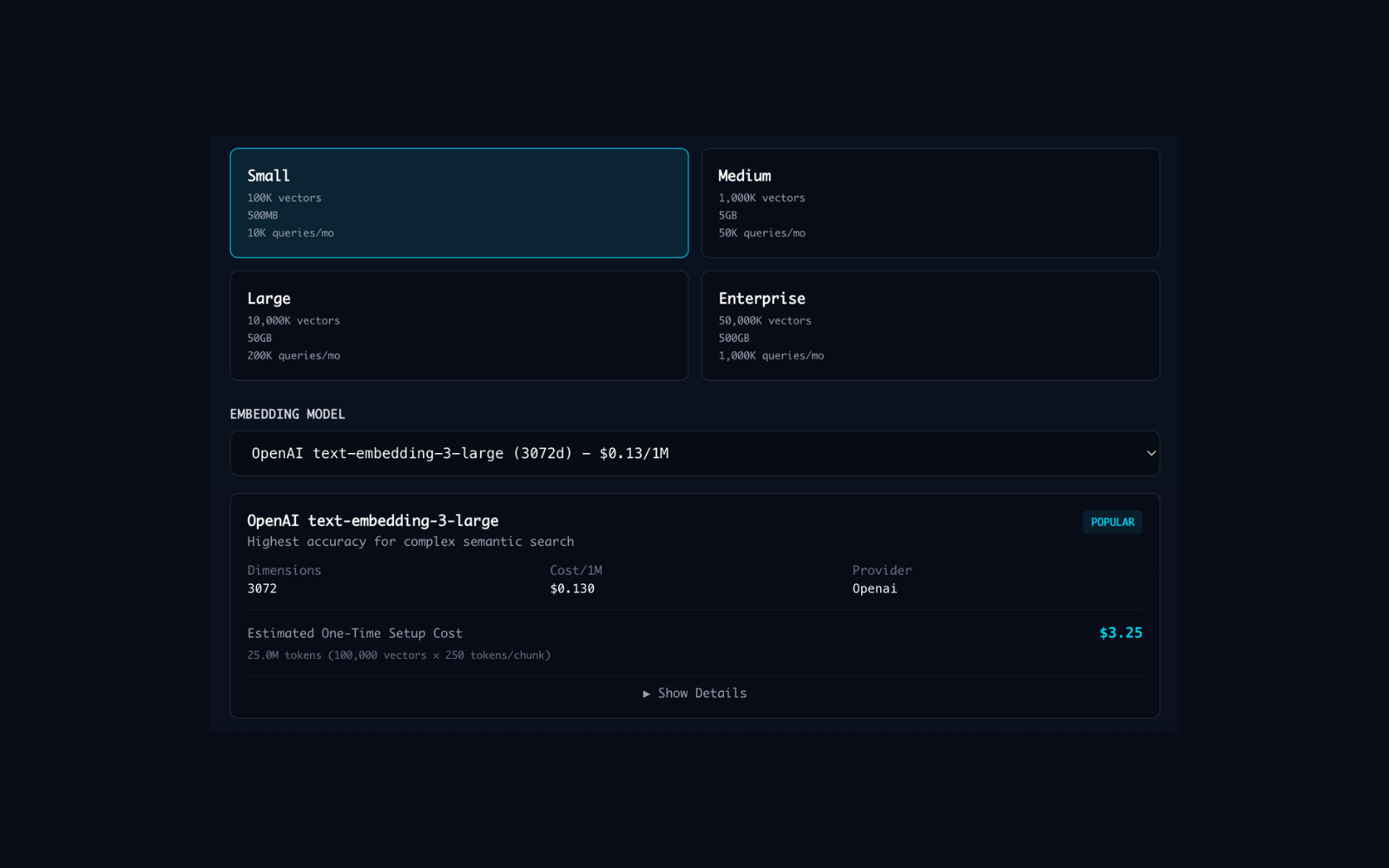
Most calculators stop at inference pricing. YSelector models the entire RAG pipeline: vector count, retrieval depth (Top-K), churn rate, and embedding overhead. The system surfaces the hidden infrastructure costs that typically go unaccounted for until production.
- ✓Vector Database Storage Costs
- ✓Embedding Generation Fees (CapEx)
- ✓Context Window Overhead
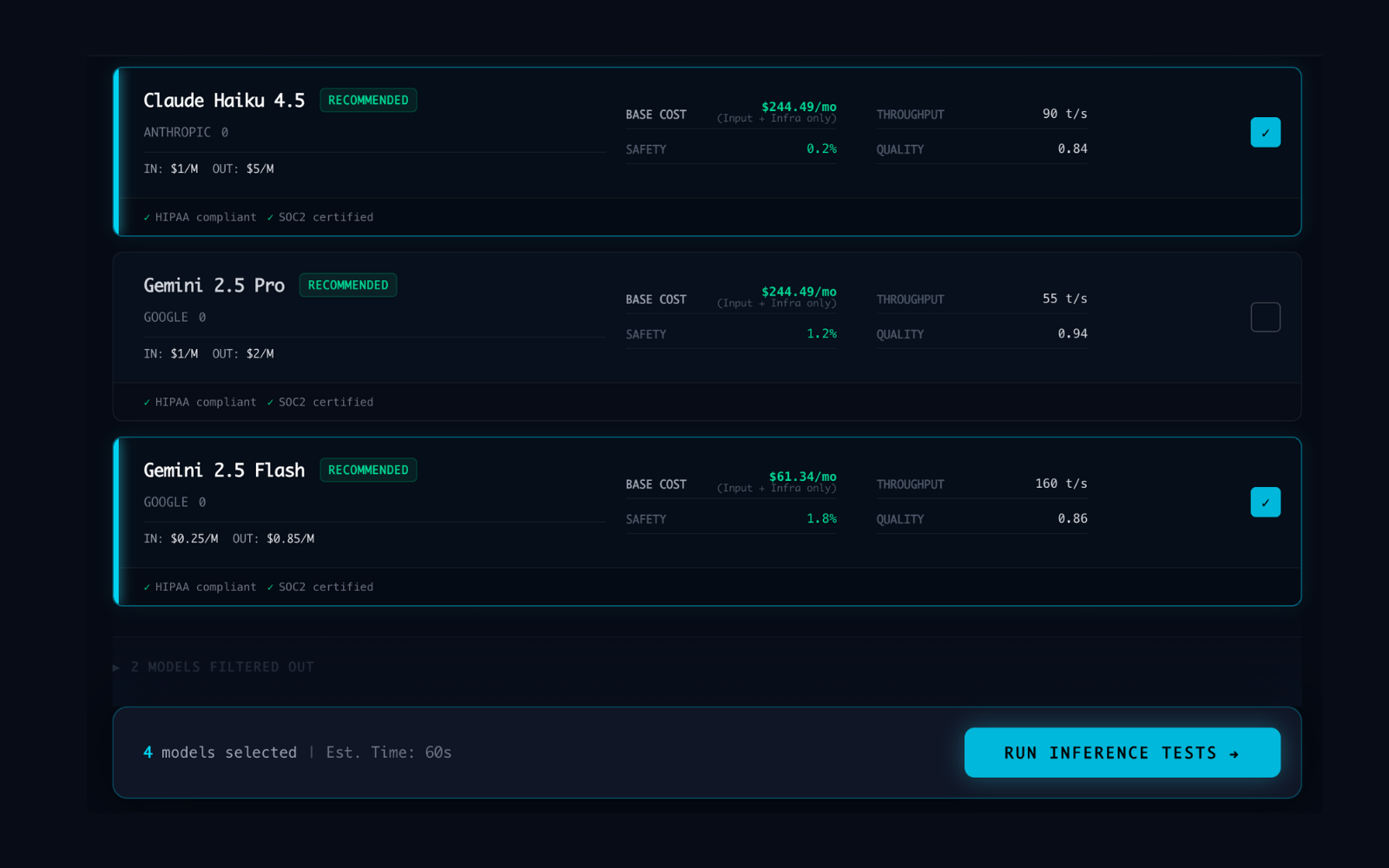
Real-Time Benchmarking
Parallel Inference
Against Real Prompts.
YSelector fires parallel inference tests across GPT-4.1, GPT-4.1 Mini, and GPT-4.1 Nano on Azure AI Foundry using a user-supplied prompt. Each response is measured on latency, token cost, and output quality. Pure text-in / text-out comparison for model selection, not agent orchestration.
Exportable Reports
PDF Cost Breakdown
OpEx, CapEx, Compliance.
The system generates exportable PDF reports that itemize monthly operational expenses (OpEx) and one-time setup costs (CapEx). It also auto-detects HIPAA & SOC2 requirements from the project description and flags non-compliant models automatically.
See a Sample Report →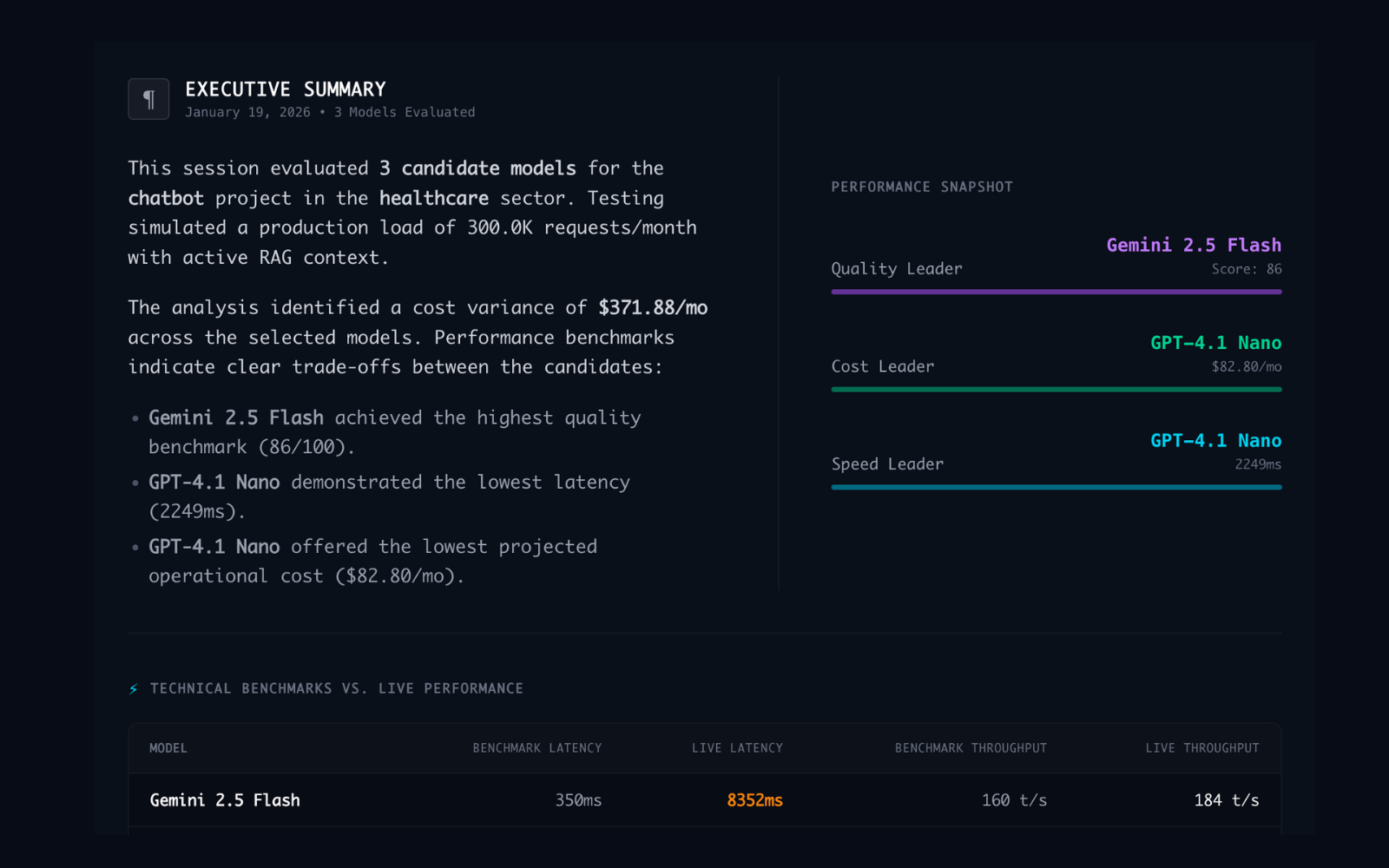
See How It Works
Walk through the full workflow: describe a project, configure a RAG pipeline, and run live GPT inference tests on Azure AI Foundry.
BUILT WITH NEXT.JS • AZURE AI FOUNDRY • GPT-4.1 FAMILY